
This article benchmarks the performance of two different Python frameworks (Django, FastAPI) and a Go framework (Pocketbase), when making GET requests that serialize 20 simple JSON objects from a relational database (SQLite, PostgreSQL). The results show that Go/Pocketbase is only about twice as fast as Python/FastAPI, which is surprising, given that Go is generally considered to be much faster than Python. We also find that, as expected, FastAPI is faster than Django, and that Go/Pocketbase’s memory consumption is much higher than for both Python frameworks.
Introduction
When developing any kind of software, you need to choose a programming language and (most likely) several libraries, to avoid building everything from scratch. There are many selection criteria (e.g. familiarity with the language/libraries). Performance is one selection criterion people often do not consider in advance.
For a personal hobby project, I wanted to sharpen my (stress test) benchmarking skills, using the benchmark results to guide me in the selection of the programming language and library.
I want to implement a REST backend service that should also have integrated ORM (Object Relational Mapper) library and have the ability to auto-generate a backend web interface, based on the Entity model classes I define. Programming-language-wise, I’m mostly familiar with Go and Python.
After some research, I found these applicable frameworks:
- Python: FastAPI and Django: both are very popular and have a large community. Django includes an admin dashboard by default. For FastAPI, there are 3rd party modules (e.g. this one or this one) that add them
- Go: Pocketbase was the most promising solution that is actively maintained
I’m a fan of boring tech that needs only 1-2 components. I’m fine with a monolithic app that runs on a single server, using a SQLite (or different) relational database as second (possibly separately deployed) component. I don’t expect much traffic (a few requests per second), which a single server can definitely handle. A simple monolith provides the best deployment flexibility: it deploys to a single VM, Kubernetes, or a PaaS such as Vercel / Fly.io / Railway.
Benchmark scenario
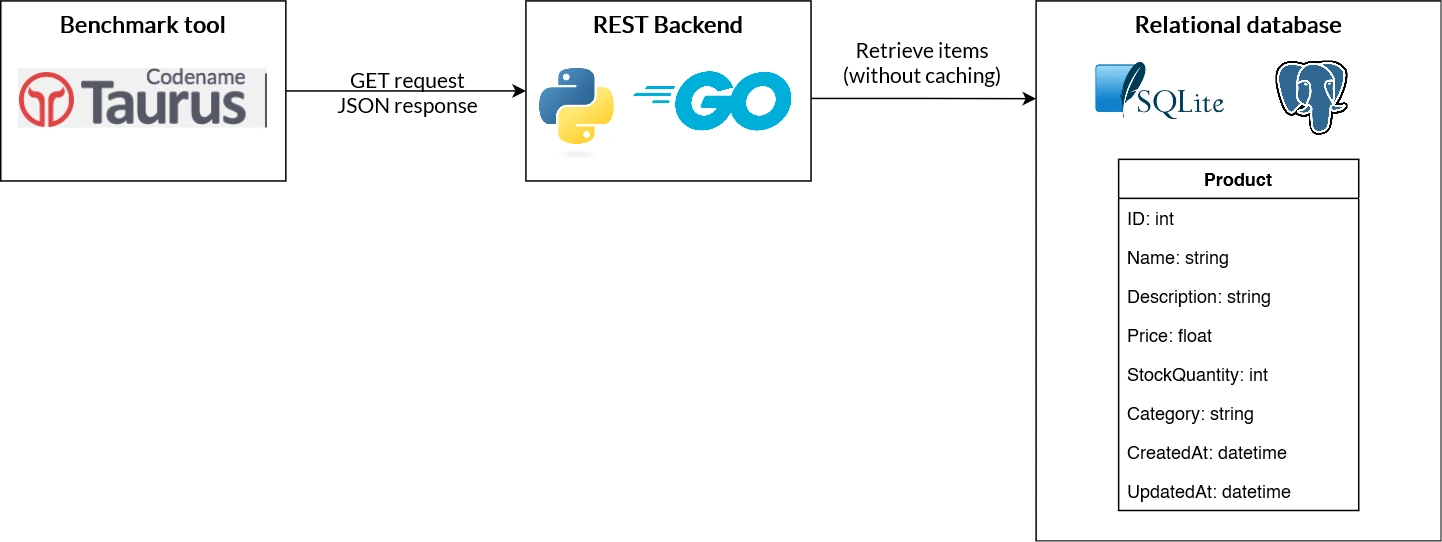
The scenario is a stress test where Gatling (controlled by Taurus) runs 200 parallel GET requests to the REST backend, for one minute. The backend (implemented in Python or Go) queries the database (SQLite file or PostgreSQL), which stores 20 Product entries (with disabled caching). The backend serializes these 20 products as JSON and returns them.
Varying database support
Pocketbase only supports SQLite, while the Python-based frameworks do support both SQLite and PostgreSQL (and several other relational database products).
Test setup and code
For each framework, I developed a minimal REST backend with the exact same functionality. I implemented the following configurable parameters:
- Number of processes/CPUs to use (run-time)
- Type of database to use, only for Python frameworks: SQLite vs. PostgreSQL (run-time)
- Only for FastAPI: whether to pre-compile the code to native code, using Nuitka (compile-time)
You can find the code here on GitHub.
I executed the benchmarks in Docker (Desktop), using a Microsoft Windows machine with a Intel Xeon E3-1230 CPU (4 physical cores, 8 hyper threads) and 24 GB memory.
Beware of unexpected background processes using CPU
Although I made sure that, during a benchmark, Docker and the WSL process (“Vmmem”) were the only processes with CPU load, I had inconsistent benchmark results at first. Digging deeper, I noticed that these performance issues only occurred right after (re)building the backend’s Docker image.
The underlying reason is that Docker Desktop automatically scans any new image for vulnerabilities in the background, which causes significant disk and CPU load. I thus disabled this behavior in the Docker Desktop settings.
To make the benchmark as fair as possible, I attempted to apply all production optimizations tricks that I know of (most of them were not successful, which I elaborate in the Results section):
- Database access: you can mess up connection pooling, or use a poorly-performing driver or access mode:
- In case of Go: Pocketbase already applies the best practices (connection pooling). To access SQLite, Pocketbase can use different SQLite libraries, depending on the
CGO_ENABLEDenvironment variable value. I compared the performance of both variants and found that the C-based SQLite library (that is used forCGO_ENABLED=1) is about 25% faster, when using multiple workers. So that is the SQLite library I used for all benchmarks. - In Python, the goal is to use async drivers and frameworks whenever possible, as this allows handling more parallel connections (alternatively, a well-scaling WSGI server, such as uwsgi, should be used, which scales the backend’s performance by running multiple Python processes).
- In case of Go: Pocketbase already applies the best practices (connection pooling). To access SQLite, Pocketbase can use different SQLite libraries, depending on the
- Code compilation: while Go is already a compiled language, Python code is interpreted. However, there are tools such as Nuitka that transpile Python code to C code, which is then compiled using a C compiler such as GCC. Also, there is PyPy that promises a better run-time performance, compared to CPython.
Research questions
Treating the benchmark like a scientific experiment, I designed a few research questions, along with hypotheses for the results, prior to running the benchmark:
- How does each framework perform (measuring requests/second, average latency per request, and peak memory usage), when running a stress test with 200 concurrent connections?
- Hypotheses:
- FastAPI should be a bit better than Django in terms of the measured metrics
- Python code compiled with Nuitka (or running on PyPy) should run ~20% faster than with CPython
- Pocketbase should be at least 10x better and also consume less memory, because it is a compiled language
- The requests/second results for PostgreSQL should be slightly better than for SQLite, because PostgreSQL server is a dedicated Linux process / Docker container, whose CPU usage is accounted for separately (incurring only I/O wait time, which can be mitigated by high degrees of parallelization)
- Hypotheses:
- By how much does providing more CPU cores improve performance? And do the frameworks fully utilize the CPU cores? (Note: for Python, we need to run one Linux process per CPU core, because of Python’s Global Interpreter Lock, which prevents that multiple threads of one process can use more than 1 CPU core). We run the benchmark twice, for 1 and for 4 CPUs.
- Hypothesis: the performance for 4 cores will use 4x the memory footprint, but only 3x the requests/second (due to Ahmdal’s law and other implementation-specific overheads). We expect a close-to 400% CPU utilization when running on 4 cores (indicating that handling the GET requests is a CPU-bound problem rather than being I/O-bound, with CPU time being most likely spent on request processing, e.g. JSON (de)serialization).
Results for Go vs Python
Raw results
Here are the raw results (raw results as CSV):
| Test name | Compiled with Nuitka | Workers | Memory (MB) | Total requests served in 60 secs | Average latency | Requests / second |
|---|---|---|---|---|---|---|
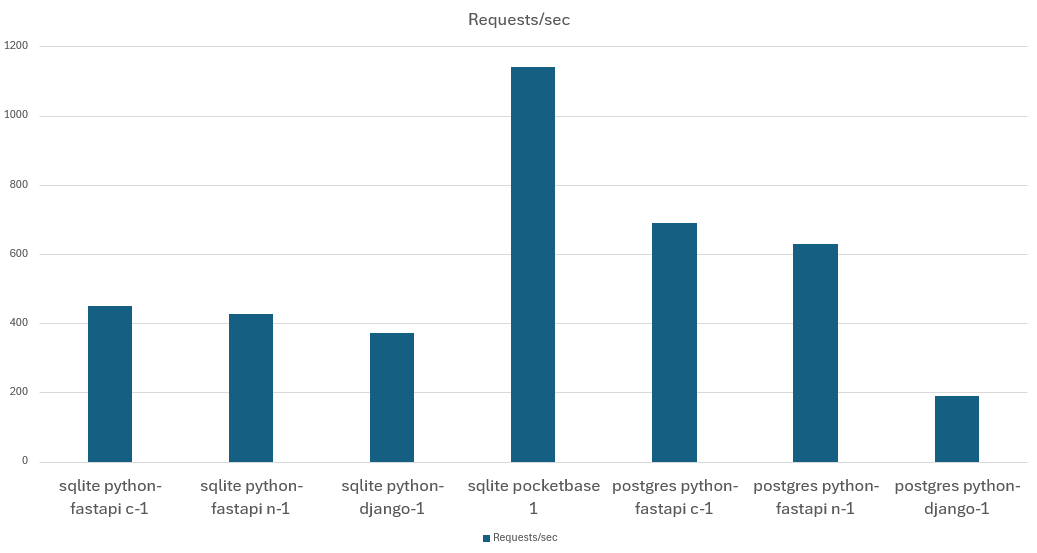
| sqlite python-fastapi c-1 | no | 1 | 48 | 27000 | 0,461 | 450 |
| sqlite python-fastapi c-4 | no | 4 | 201 | 81895 | 0,152 | 1364,91 |
| sqlite python-fastapi n-1 | yes | 1 | 47 | 25600 | 0,486 | 426,66 |
| sqlite python-fastapi n-4 | yes | 4 | 203 | 80000 | 0,157 | 1333,33 |
| sqlite python-django-1 | — | 1 | 72 | 22300 | 0,561 | 371,66 |
| sqlite python-django-4 | — | 4 | 152 | 55100 | 0,208 | 918,33 |
| sqlite pocketbase 1 | — | 1 | 66 | 68500 | 0,182 | 1141,66 |
| sqlite pocketbase 4 | — | 4 | 300 | 193500 | 0,065 | 3225 |
| postgres python-fastapi c-1 | no | 1 | 50 | 41300 | 0,3 | 688,33 |
| postgres python-fastapi c-4 | no | 4 | 200 | 109300 | 0,114 | 1821,66 |
| postgres python-fastapi n-1 | yes | 1 | 52 | 37800 | 0,329 | 630 |
| postgres python-fastapi n-4 | yes | 4 | 268 | 101900 | 0,122 | 1698,33 |
| postgres python-django-1 | — | 1 | 87 | 11300 | 1,114 | 188,33 |
| postgres python-django-4 | — | 4 | 182 | 41500 | 0,302 | 691,66 |
As for the naming scheme: the “c-1” or “n-1” (that you find for Python benchmarks) refers to whether CPython or Nuitka was used, the number indicates the number of CPU cores.
Requests/second performance
Single core requests/second:
Requests/second when using 4 cores:
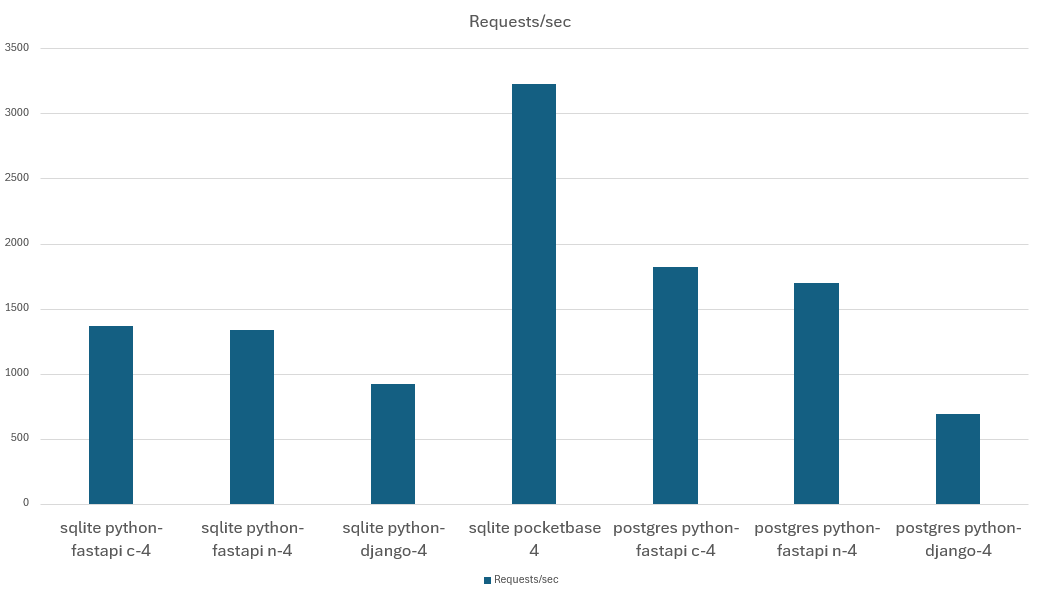
Insights for Go vs. Python
As expected, Go (Pocketbase) is faster than any Python solution, but not by the expected order of magnitude. Pocketbase is only 2.36x faster than the fastest, SQLite-based Python solution (FastAPI). And if we compare Pocketbase with FastAPI on PostgreSQL, Pocketbase is only 1.77x faster than FastAPI.
Insights for Django vs. FastAPI
As expected, FastAPI is faster than Django:
- When using SQLite, the performance benefit is rather small: FastAPI is 21% faster in single-core mode and 48% faster in 4-core mode than Django
- When using PostgreSQL, FastAPI’s async mode kicks in, making FastAPI 3.6x faster than Django in single-core mode, and 2.6x faster in 4-core mode
Regarding latency, the results are as expected in my hypothesis. The latency is inversely proportional to the requests/second, and Go/Pocketbase offers the lowest latencies.
Failed Python performance optimization attempts
I attempted quite a few performance optimizations which did not work out:
- Django async mode: While Django keeps improving its
asyncsupport (see docs), it did not work well for me. I had to revert the corresponding commit and use the traditional synchronous mode (wsgi instead of asgi and “async def” view-methods). The problem was that, in async mode, Django tried to create over 100 connections and did not properly use its database connection pool (as it does in sync mode). There are many discussions about this topic (see e.g. here or here) and ultimately, the Django developers suggest to use pgBouncer to alleviate this problem. To reduce the scope of this experiment, I decided not to go down this route. Maybe the connection pool feature that is to be introduced in Django 5.1 in August (see here) might fix this issue. - FastAPI connection pool tuning: in the FastAPI implementation of the REST backend, I chose TortoiseORM as ORM library. I tuned the optional PostgreSQL parameter
maxsize(see docs), increasing it from its default value (5) to larger numbers (e.g. 50). However, doing so had a negative performance impact regarding the requests/second (just ~5%, but still noticeable …). - Code compilation with Nuitka: for the FastAPI project, I used Nuitka to transpile the Python code to C, and then compile it to native code. The run-time memory usage (of CPython vs. Nuitka) was about the same, but the requests/second performance of the Nuitka version was 2-9% worse than with CPython! Also, transpiling + compiling the code took about 10 minutes. Thus, using Nuitka was definitely not worth it, in this context.
- PyPy and dependencies: PyPy promises to be a drop-in replacement for CPython, offering better performance. However, I could not even install the dependencies, because they include native modules. In that case, PyPy’s “
pip install” attempts to recompile these dependencies, which fails for some libraries (e.g. asyncpg, or orjson which is a dependency of FastAPI) for various reasons (example: “asyncpg/protocol/record/recordobj.c:474:5: error: unknown type name ‘_PyUnicodeWriter’; did you mean ‘PyUnicode_WriteChar’?”). Trying to fix this would mean to go down a very deep rabbit hole, which was beyond the scope of this experiment.- Note: for the Django project, installing dependencies did work, but the server (uwsgi) would not start, due to the following error: “
uwsgi: unrecognized option '--module=myproject.wsgi:application'getopt_long() error“. I gave up after an hour of researching.
- Note: for the Django project, installing dependencies did work, but the server (uwsgi) would not start, due to the following error: “
Multi-processor scaling
My expectations regarding performance increases were mostly correct:
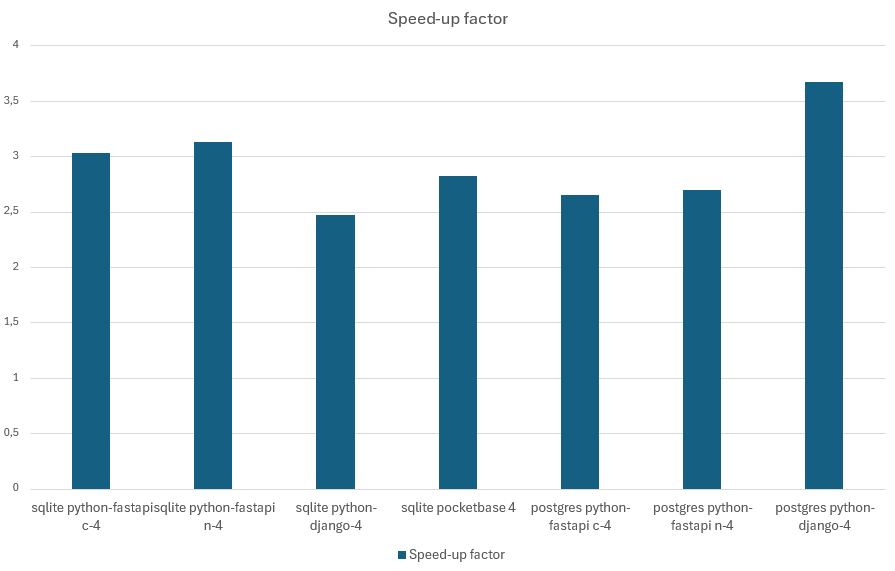
As you can see, the performance improvements regarding requests/second are in the range of 2.5x – 3.6x, and the latencies improved by about the same factor.
Also, all frameworks consistently used the allocated CPU cores to their full extent (e,g, close to 400% CPU utilization for the 4-core scenarios).
Memory usage and leaks
One of the most interesting findings is the memory usage.
First, Python’s memory usage is (slightly) below the one of Go. That directly contradicts my expectations of a compiled language having a smaller memory footprint.
Second, Python’s memory usage stays constant (as I would expect) over time, whereas Go’s memory usage keeps increasing: I ran another round of benchmarks that last longer (4-5 minutes, instead of 1 minute), repeating the benchmark a second time after waiting for a few minutes (to observe whether any memory garbage collection occurs). In case of Python, the memory usage always remained constant. In case of Go, memory use grows without bounds:
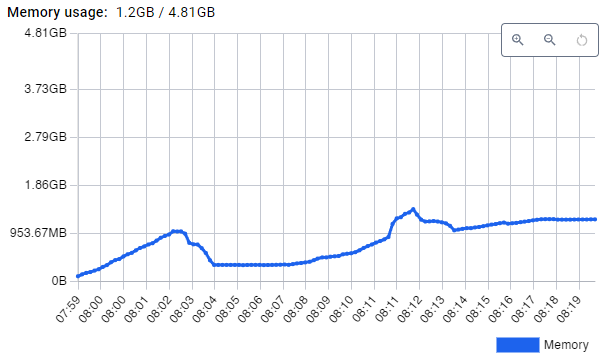
The above image shows the Docker container performance stats for the Pocketbase container. In the first benchmark, memory use increases to almost 1 GB, then a GC cycle seems to clean up memory, but ~450 MB remain. The second run increases memory use to 1.6 GB, GC reduces it to about 1.1 GB. Continuously repeating the 5-minute stress test a few more times ultimate lead to an out-of-memory (OOM) kill of the Pocketbase server. Note: this problem only occured with GOMAXPROCS=4, not with 1.
One approach to limit Go’s memory hunger is to set the GOMEMLIMIT environment variable, which configures a soft limit. The following image shows the memory usage when setting GOMEMLIMIT to 200 MB:
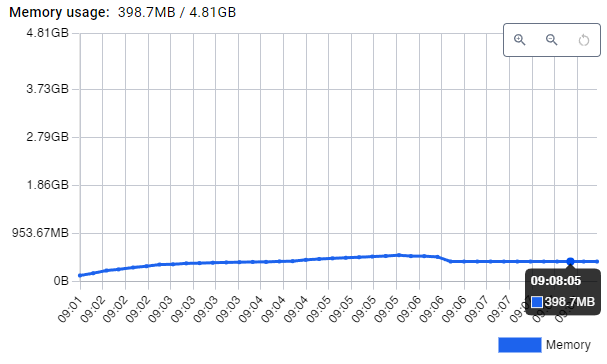
As expected, the memory use is now much lower. However, interestingly, the requests/second (and latency) performance decreases, the longer the benchmark test runs, down to a level where the performance of Pocketbase is about the same as for FastAPI (that is, performance decreases by about a factor of 2).
Conclusion
As expected, different use cases will produce very different performance characteristics. There are numerous blog articles (and scientific papers) that attest that compiled languages (like Go) are 10x – 100x faster than interpreted languages (like Python). But these benchmarks typically test numeric computations, and in this post we’ve seen that running a REST backend service will yield very different results. Thus, beware with drawing false conclusions when reading other people’s benchmarks.
The big question is: should you even do any benchmarks for your project or product? It depends. Looking at the raw results, even the worst-performing framework (Django) offers rather good performance (188 requests/second with PostgreSQL and a single core) which would suffice for my use case. Consequently, I’d argue that doing such benchmarks only makes sense if:
- a) you are fairly sure you will run at a very high load, with hundreds or thousands of requests per second (in my daily work, such projects are rather rare), or
- b) you want to utilize your hardware as much as possible, thus you would deploy multiple (different) backends onto the same server, each backend running only with a single process and CPU throttling (e.g. throttling to 0.2 vCPUs). As added benefit, if the backend uses as little resources as possible, you can expect your bill to be lower, for providers such as Vercel or Fly.io, where you can get cheap “VMs” with, say 256 MB RAM.
What has your experience been with such kinds of benchmarks? Please let me know in the comments.
Hi Marius,
Great article. I noticed the Django SQLite test uses the default settings, while the PocketBase uses the SQLite in WAL mode. https://pocketbase.io/faq/ (question 6)
A blog discussed the optimized SQLite configuration for Django (linked to the Django 5.1 section): https://blog.pecar.me/sqlite-django-config#in-django-51-or-newer. And more explanation is here: https://blog.pecar.me/django-sqlite-benchmark
By applying the configuration, I guess the gap between Django/FastAPI and PocketBase will be narrowed.
Hey. Good to know that Django offers more SQLite performance optimization options.
However, for the benchmark I discuss in this article, where we measure READ performance, WAL mode on/off has no impact (WAL mode improves WRITE performance).
You’re right. WAL mode doesn’t offer benefits in a pure read scenario. However, the SessionMiddleware might trigger a database write for an anonymous request by assigning a unique session ID as a cookie and storing it in the database. If my assumption is correct (though I haven’t confirmed it yet), each benchmark request would generate two SQL operations: a write followed by a read. In that case, WAL optimization would make sense. Alternatively, you could use a cache backend for session storage.
My main point is that ensuring database settings are aligned can help avoid unexpected issues.
Yes, in that specific instance you might be right 👍
I did a quick test – enabling WAL for Django (and other optimizations mentioned in the referenced blog) provides only a small benefit (+8% RPS) for this simple scenario.
name, RPS, Latency
sqlite python-django-1, 447, 0.343
sqlite python-django-4, 1308, 0.122
sqlite python-django-1 +WAL, 487, 0.336
sqlite python-django-4 +WAL, 1421, 0.116
sqlite pocketbase 1, 1194, 0.127
sqlite pocketbase 4, 3416, 0.042
The PocketBase RPS remains 2.x times higher than Django.
Hey, thanks a lot for doing the test. While the improvement is not much, still, 8% is better than nothing ;).
It turns out that the Django session middleware is lazy, and the /products endpoint only generates 1 read SQL. That explains why the WAL optimization didn’t have much impact on my benchmark result. Anyway, the original benchmark and its conclusion are quite correct. 👍