
CI/CD is the process of fully automating tasks such as building, testing and deploying your software. Instead of running these tasks manually, on a developer laptop, you have them executed on a server all the time. In this article, I dive deeper into the definition of CI/CD and related terms, explain the background of CI/CD, as well as its advantages and disadvantages.
Introduction
The term “CI/CD” has become omnipresent in the media typically consumed by developers. CI/CD is short for Continuous Integration & Continuous Delivery/Deployment. CI/CD is being hailed as the savior of your software project. The simple promise: just create CI/CD pipelines, and your project will be free of bugs or technical debt, and will be delivered on schedule.
Unfortunately, things are not that easy. If you don’t understand the background of CI/CD, the continuous development methodology, or if you don’t have a good understanding of the different disciplines and skills needed for creating the tasks that run as part of a CI/CD pipeline, you are effectively just cargo-culting. The remainder of this article is my interpretation of what CI/CD is, and why you need it. We will start with examining the background, define various terms, and also look at the kinds of tasks that should be part of your CI/CD pipelines.
GitLab CI/CD
This article is generic and not dependent on any concrete CI/CD implementation. If you want to learn more about using GitLab for CI/CD, check out my other article, where I go into GitLab-specific details of CI/CD pipelines.
Background: continuous development methodology
The core idea of CI/CD is to save you money when developing software, via automation. That means that you automate as many tasks as possible that happen between “developer pushes code changes to Git” and “your customer can use the features on the production system”. Automation has advantages (which generally hold, not just for CI/CD), such as:
- It is much cheaper to have a machine execute some code in an automated way vs. paying a person to do it manually, because code executes faster than a human can type commands.
- A machine will do a job much more reliably than a human (who may e.g. forget a step when pushing a change to production, breaking the entire system) → thus, automation saves costs indirectly, because you no longer have to fix mistakes that resulted from humans doing an unreliable job.
The C (continuous) in terms like CI or CD refers to the fact that the concrete tasks that are part of CI or CD (more details below) are executed all the time on some CI/CD servers, e.g. every hour, or on every Git push. This is an improvement over the “traditional” development process, such as (repeated) Waterfall. Here, activities like packaging a software, or running tests, are often done or triggered manually, e.g. at the end of a development life cycle phase – e.g. once per month at the end of a sprint. Such manual execution is a bad idea, because it is expensive:
- The chance is high that you skip (or delay) writing tests of your app’s functionality or security. Consequently, your system is less reliable, and you are accruing technical debt without even realizing it.
- This is fixed by doing Continuous Integration, which mandates that you have a continuous testing mindset, where you write tests alongside your code all the time.
- The chance is high that you develop features for many months which the client actually doesn’t need.
- Continuous Deployment fixes that. A CD pipeline makes deploying changes effortless – thus, you deploy changes all the time, and receive customer feedback much earlier.
Continuous development is not free
While the advantages are clear, you must be aware that introducing CI/CD is not free! Essentially, you are front-loading (“shifting left”) the workload. You need to create (and maintain) the scripts that automate the tasks that (without CI/CD) were done manually. In some cases, e.g. system testing, this can become rather challenging. Before introducing a new CI/CD automation task, think clearly about the costs (of implementing it) and the potential cost savings the automation will yield.
Challenges of setting (and maintaining) CI/CD pipelines include:
- Initial effort to build the automation scripts (and configure the pipeline to run them only in the right circumstances).
- Maintenance of the automation: both the CI/CD system, and all the technology used in your automation scripts, change over time.
- Performance issues: even if all your automation scripts work as intended, they may be too slow (and pipeline executions are stacking up) → you need to invest time to optimize them.
- Issues with pipeline/job-system itself, e.g. debugging problems with a (buggy) pipeline runner.
Fortunately, you can gradually introduce CI/CD. You can start with just one automation step (e.g. building your software), and extend it over time.
Definition of terms
Let’s take a look at the meaning of some basic terms:
- Continuous integration means that whenever a developer pushes code changes to Git, the server analyzes the code (e.g. linting), builds / compiles the app, and runs automated tests (that you wrote, e.g. unit or integration tests). It is called Continuous Integration because you typically have multiple developers pushing code changes independently from one another. Changes made by one developer may have side effects, breaking other developers’ changes, or breaking other parts of the system the developer did not touch. The CI automation ensures that those changes breaking other changes are not integrated. The fact that the CI pipeline is always executed (and thus we don’t have to rely on the developer to execute such scripts locally on their laptop) is beneficial by itself (→ high reliability). This is especially true for very large systems where a developer cannot possibly understand all parts (or their interdependencies) of the system, and may not even have all parts of the system installed locally.
- Continuous Delivery means to package your application (which was built during in CI, thus: building != packaging) so that it is ready for deployment (e.g. as Docker image or setup.exe). The packaged application may even be fully automatically deployed to test or staging environments (but not production environments). Then you can also run specific integration or system tests in that environment. Getting a packaged build into the production environment must be very easy, by flipping a switch.
- Continuous Deployment is an extension to Continuous Delivery: with everything else being equal, now the changes are also pushed to production in a fully automated way. Flipping a switch is no longer necessary.
Ambiguity of definions
The definition (and separation) of Continuous Delivery vs. Deployment can vary among different sources. GitLab, for instance, states that for Continuous Delivery, deployment does not happen automatically (but always requires the final press of a button), whereas other sources state that deployment does happen automatically, but only for testing environments.
Similarly, you will find people who claim that the D in “CI/CD” stands for Delivery, some also state it stands for Deployment, and others again say it stands for both.
Pipelines, jobs and runners
On a conceptual level, CI/CD systems like GitLab CI or GitHub Actions let you define pipelines (called workflows in GitHub Actions), which contain one or more jobs. Each job is executed by a runner, of which there may be several. Thus, multiple jobs may run in parallel, whenever possible.
The below image is a visualization of a GitLab CI/CD pipeline with 4 jobs, where the 2 test jobs can run in parallel, because they don’t depend on each other:
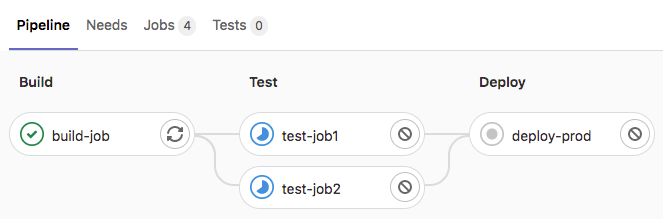
A pipeline is typically defined using a YAML or JSON file that contains the jobs, as well as the events that trigger the pipeline. Typically, a pipeline is triggered whenever one (or more) commits were pushed (running the pipeline for the most recent commit of that push), but there many alternative events, e.g. the creation of a PR / Merge Request, or a regular schedule (think: Cronjob). If any of the jobs of a pipeline fail, the developers will get notified (e.g. by email), so that they can investigate the issue.
As for the runners, you can either use so-called shared runners , or dedicated self-hosted ones. Shared runners are offered by the people hosting the GitLab/GitHub/… instance. They are called “shared” because they run pipelines of many projects, which thus share the runner. Alternatively, you can run your own “self-hosted” runner and register it with your project. The downside is that you need to take care of installing and maintaining that runner. The upside is the increased speed with which your pipeline is executed, because you would configure the runner to only serve your own projects.
Typical CI/CD tasks
Let’s take a look at typical tasks you would have your CI/CD pipelines execute, separated by the CI and CD stage.
Continuous Integration
- Code analysis
- SCA (Software Composition Analysis): checks the 3rd party dependencies you use in your software for known vulnerabilities (CVEs) or available updates, e.g. Renovate Bot, dependabot, safety (Python)
- SAST (Static Application Security Testing): scans your own code for vulnerabilities (e.g. potential stack overflows, etc.), e.g. SonarQube or PMD (cross-language), Checkstyle (Java), bandit (Python), etc. See also this list.
- Code style (e.g. Linting)
- Building / compiling your code – in general: getting it into an executable state. For interpreted language, such as Python, this could mean to just install the necessary 3rd party dependencies.
- Running tests, of those kinds that already make sense at the CI stage, e.g.
- Unit tests: testing individual classes
- Component tests: testing several classes which form a module performing a specific function
- Integration tests: testing that multiple (but not all) components (which are already tested individually) play well together – typically requires mocking of those components excluded from that specific test.
Continuous Delivery & Deployment
- Packaging your application (e.g. as Python wheel, Docker image, Windows setup.exe, macOS App Bundle, etc.)
- Publishing (=uploading) the package to some server or registry (e.g. uploading a Docker image to an OCI registry)
- Software tests:
- Smoke tests: simply starting your packaged application, to see whether it crashes (test passes if it doesn’t crash).
- System tests: testing the system’s overall functionality (including all of its components)
- E.g. End-to-end tests that test a sequence of input-output-input-output…. interactions (e.g. logging into a website and clicking menu items, expecting certain pages to be returned)
- Performance tests, e.g. load tests or stress tests (they both test how your application behaves under high load – stress test are putting extreme amounts of load on the application to see whether it crashes or recovers)
- Installation tests, which verify that your software can be installed (and upgraded) successfully
- Security checks with DAST (Dynamic Application Security Test) tools, such as Zed Attack Proxy (ZAP), which try different attacks against a running application instance
- Deployment of your packaged application in an environment
Test attribution to CI or CD
Depending on the kind of software you are building, you may also attribute system or performance tests to the CI stage (rather than CD), e.g. if you are building a simple CLI application. However, if you are building a containerized microservice-based application, you must have built the images first, before you can run system-level tests (or other kinds of tests) against them.
Conclusion
Building CI/CD pipelines is a necessary step if you want your long-lasting software project to succeed. The long time frame makes it worthwhile to actually build and maintain the pipeline. In other words: setting up elaborate CI/CD pipelines for a small prototype is not worth the effort.
There are many CI/CD tools (free and commercial) on the market, like GitHub Actions, GitLab, Jenkins, Jenkins X, or CircleCI. However, ultimately it’s not about choosing the “right” tool, because they are all very similar in terms of functionality. It is much more important that you live the continuous development methodology, and understand the basic principles behind each task a CI/CD pipelines executes. If you don’t have any people who know how to write tests, or harden your application’s security, what is the point of writing some half-assed unit tests or buying SCA / SAST software (whose reports you don’t understand anyway)?
It normal that you will struggle during the starting phase. It’s not easy to decide which tasks to automate first. It is not always easy to estimate the time savings, and it is close to impossible to estimate the costs of implementation. You can start out by automating those things that you annoy you the most (and that also take an considerable amount of time). To avoid that developing the pipeline comes to a halt, make it a habit to allocate resources (e.g. eight hours per month) to continuously improving the pipeline over time, making it a part of your sprint.