
In this article I compare several approaches for running compliance checks, like validating Git commit messages with a regular expression, or linting your code. I explain how these checks can either run in your IDE, in a local pre-commit hook, a remote pre-receive Git hook, or as part of your CI pipeline. I compare these four execution environments and provide recommendations for how to choose the solution that best suits your needs.
Introduction
In software projects you typically have a bunch of rules that apply to your source code and the commits, which you want the whole team to comply with. Concrete examples could be:
- Git branch names should follow a certain format (e.g. have a min/max length and start with a issue/ticket number)
- Git commit messages should follow a certain format (e.g. conventional commits, or start with an issue/ticket number)
- Formatting/linting rules that apply to specific files (e.g. ESLint with a specific configuration for a Node.js project)
The purpose of such checks is to reduce the code reading time, and therefore speed up code reviews, and to enhance the traceability between your committed code and the corresponding tickets (e.g. managed with Jira).
Such compliance checks typically execute quickly. For the best developer experience, they should be executed as early as possible – ideally while the developer creates the content that is being checked. The more immediate the feedback is, the faster and easier the developer can fix any detected violations.
In this article I present four different methods for implementing such checks, and compare their advantages and disadvantages. These are:
- IDE-based linters
- Local Git hooks
- Remote Git hooks
- CI (Continuous Integration) pipelines running your linters
The following image illustrates where the methods are being placed:
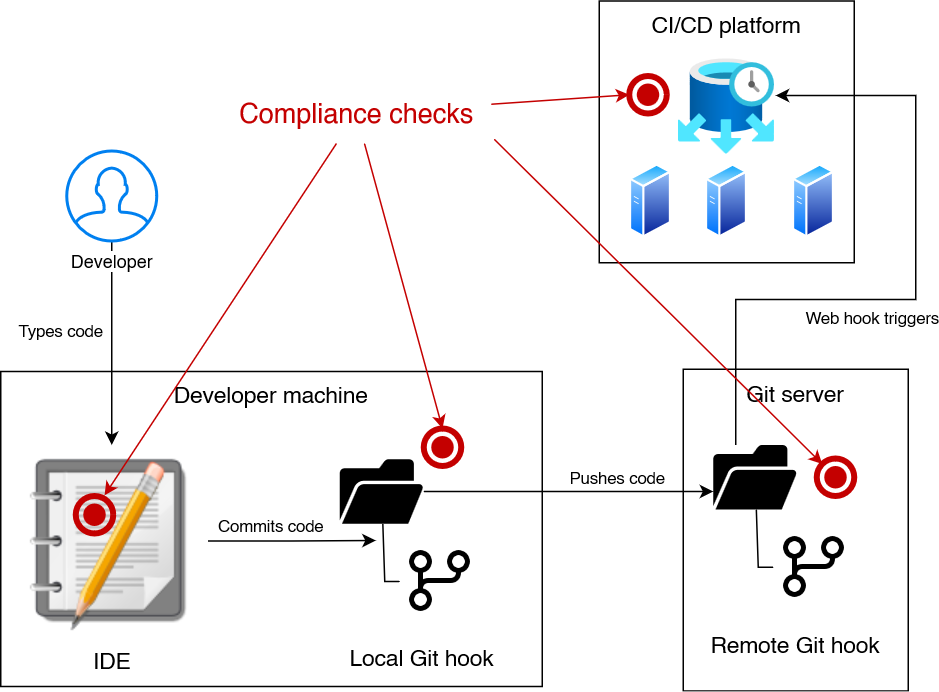
IDE-based linters
If your development team uses a well-defined set of IDEs, it makes sense to research the capabilities of the IDEs (or available plug-ins) regarding linting. IDEs offer immediate feedback to the user, e.g. by highlighting code that violates linting rules, and they often offer automatic corrections (like a spell-checker).
For instance, if you wanted your commit messages to conform to a certain schema (such as conventional commits), you could either lint them with this plug-in, or use this plug-in that offers a beginner-friendly multi-step dialog that ensures that your commit messages have the correct form.
The main disadvantage of IDE-based linters is that they are IDE-specific, and that they require explicit installation and configuration, which users might forget doing.
Local Git hooks
As documented here, Git offers client-side hooks that are executed locally on your machine, when specific events occur. For instance:
- Events that occur prior to committing (see the hooks named
pre-commitorcommit-msg) - Events that occur prior to pushing (
pre-push)
Local Git hooks are similar to IDE-based linters, but they are command-line Bash scripts that work regardless of the IDE. Like IDE linters, local Git hooks also need to explicitly installed by the developer, typically by copying a Bash script (the hook) to “<project-root>/.git/hooks/<hook-name>“.
Although Git hooks are just Bash scripts (even on Microsoft Windows machines, where Bash-based hooks run in a MSYS2 environment), they can call any other locally-available CLI tooling. You can go about this in two ways:
- Use any tooling installed directly on the developer’s machine, e.g. a Python interpreter, or the pre-commit.com tool. The main disadvantages are that this requires everyone in your team to install these tools, and that version drift might happen (e.g. when one of your team members uses an outdated Python interpreter that causes the Git hook to behave differently on their machine).
- Use Docker images: you could package the tools into a Docker image, which lets you to fix the tooling and auto-update them when needed. The main disadvantages are that Docker needs to run while running the hooks, and that hooks might execute very slowly, e.g. if there are image updates which need to be pulled or rebuilt prior to running the hook. In that case, a
git commitcommand might hang for a minute or two.
Because option #2 has the potential to be slow, I would advise against implementing it. Slow pre-commit hooks are especially bad for the development experience, particularly if your developers commit often!
Remote Git hooks
Git also offers server-side hooks, such as pre-receive, which are executed remotely on the Git server. If you use SaaS platforms such as GitLab.com or GitHub.com, server-side hooks are not available at all (for security and technical reasons). You need a self-hosted server, such as GitHub Enterprise, but the setup and configuration is often clunky.
Even if you manage to set server-side hooks up, they are typically limited to Bash. Although you could install additional tooling on the Git server that runs the hook, you might not want to do so: it is likely that your Git server hosts many projects, and if they all require different tooling in the server-side hook, you end up with tool conflicts. If you really want to use server-side linting/tooling, you are better off using CI pipeline linters, described next.
CI pipeline linters
If you are wondering what CI means, see my previous article. Assuming that you use a CI/CD platform, you can simply run all checks as part of a CI job. The main advantages are:
- High reliability: the jobs will always run, because they are automatically triggered on a push. It cannot happen that someone “forgets” running them.
- You can use any tooling you want (beyond Bash): it is very common to pre-configure your CI build agents with often-needed tools (or download them on-the-fly).
- Depending on the CI/CD platform, there are often existing templates that already solve common checks for you, see e.g. https://commitsar.aevea.ee for checking the compliance of commit messages.
There are a few disadvantages, though. The developer receives feedback quite late: after the push, they need to wait for a minute or two to see the results. Another problem is the need to rewrite history: for instance, if your CI job determines that the commit message format is incorrect, developers need to rephrase the commits locally, and then do a (dangerous) force-push.
Comparison
The following table compares the different options:
| IDE | Local Git hooks | Remote Git hooks | CI pipeline | |
| Feedback speed | ➕➕➕ Immediate, while typing | ➕➕ At commit time | ➕ At push time | ➖➖ A minute after pushing |
| Flexibility (regarding tool choice) | ➖➖➖ Limited to IDE features / plug-ins | ➖ Only locally installed tools | ➖➖ Limited to Bash | ➕➕➕ Any tool imaginable |
| Reliability | ➖➖➖ | ➖➖ | ➕➕➕ | ➕➕➕ |
| Other issues | Support depends on IDE | Tool drift | Not available in SaaS systems | Requires force-push when rewriting history |
Conclusion
Automated checks are a boon to software quality. Thanks to the consistency they establish in your code and your commit messages, reading code is faster and more fun.
In this piece I presented the four available options for these checks, each with their own advantages and disadvantages. You probably wonder how to choose the best option for your software project. As a rough guideline, you should first ask yourself whether consistency is just a “nice to have”, or a hard requirement (e.g. because regulatory rules might demand some level of traceability between Jira tickets and your code):
- If you have a hard requirement, choose CI pipeline jobs/linters, because of their high reliability.
- Otherwise, local Git hooks are a good choice, unless everyone in your team uses the same IDE which can lint exactly those aspects you care about.
However, you don’t necessarily need to decide: you can combine multiple approaches. For instance, you could have a local pre-commit Git hook that checks the branch name and commit message formats prior to pushing them, but additionally have CI linting jobs that validate the same data. However, there is extra maintenance effort to ensure that both approaches are in sync (e.g. check the same commit message format) so that they do not contradict each other.
On a final note, I highly recommend visiting this page of the pre-commit.com framework, to get an idea of what kinds of linting rules exist. Even if you do not plan to use the pre-commit.com framework itself, you can build alternative implementations yourself for interesting linter-jobs (e.g. checking that files end with a new line). What is also interesting about that framework is that you can also run it in a CI job (see documentation).