Writing technical project documentation using proprietary formats like Word, Google Docs or Confluence has numerous disadvantages. Plain text documentation, committed to a VCS like Git, can overcome these disadvantages. This article presents the markup languages Markdown, Asciidoc and reStructured Text used for plain text documentation files, how they compare, and which tools exist to render plain text documentation to visually pleasing formats such as HTML or PDF.
Introduction
Typically, technical projects require writing (and maintaining) a corresponding documentation, such as software architecture documents (SAD). As one would expect, documentation is comprised of a bunch of documents or web pages filled with structured text and diagrams, with hyperlinks facilitating the navigation between sections.
The documentation is often done with proprietary technologies. For text, people often use Microsoft Word documents, or use cloud-based services such as Google Docs documents or Confluence wiki pages. Graphs are created and stored in formats such as Visio, pixel graphics (png, jpg), or are also created in the cloud, e.g. using diagrams.net (formerly draw.io). In this article, I will point out the disadvantages of this approach, and present a better alternative: plain text documentation using a markup language, as shown in the title image.
Disadvantages of using proprietary formats
First off, I sympathize with everyone who uses proprietary formats. Their clear advantage is that people are already familiar with these tools from other contexts, and documents are created with WYSIWYG editors, which are easy to learn and handle.
On the other hand, there are numerous disadvantages:
Advantages of plain text documentation
Instead of using proprietary formats, more and more people put documentation as plain text files into a version control system (VCS) such as Git, next to their code. There is a whole movement called “documentation as code”, advocating this practice. The general idea is that you describe both structured text and diagrams in plain text files, which you convert to a consumable, nice-looking form (such as HTML or PDF) for the viewer.
This has several advantages:
Challenges with plain text documentation
Unfortunately, using plain text for documenting is not a straightforward process. Plain text documentation is not expressive at all, nor pleasant to look at. How would you create a table, mark a sentence as “bold”, or designate that a specific line is a H1 type headline? Things become even more complex when you want to create drawings, which I discuss in a separate article! Let’s focus on text documents for now.
The solution to this problem is to use markup languages. They offer a (more or less) standardized notation for formatting and structuring text, and come with a tooling ecosystem. This includes tools that convert your plain text file to some other format for which readers are a commodity, like HTML or PDF. Also, you will need editors that help you create those plain text files, at least when starting out, as the markup syntax is still unfamiliar.
Choosing the right solution involves answering two sub-questions:
- Which markup language should I use? The criteria should be that it is easy to learn, there is sufficient tooling, and the syntax is readable even as plain text, so that you can interpret a VCS diff.
- How are the markup documents rendered? You want your non-technical users (who don’t have conversion tools at hand, nor are they experts in the markup syntax) to be able to view the rendered, converted documentation, e.g. as HTML or in any other format for which the user most likely has a rendering software.
These two questions cannot be answered independently. Any specific choice you make for one question will limit your options for the other one. In the end, this is good, as it puts a quicker end to the analysis paralysis ;).
Markup languages
Let’s take a look at three markup languages, which are often recommended for creating technical documentation.
Markdown
Markdown was developed in 2004 as a nicer-to-read (and write) alternative to using HTML, with blogging being the core use case. The author wanted an easy-to-use syntax for common formatting tasks, like creating lists, code listings, headlines, links, etc. However, Markdown’s original 2004 version lacked features (such as tables) and many implementations were created that extended Markdown, resulting in dozens of Markdown flavors. The CommonMark project was created, to get an overview and to build a “common” standard. Apart from having a complete specification, its wiki lists implementations supporting CommonMark’s spec, and also offers a list of Markdown flavors. While some say that the lack of a standard is a serious problem, because different editors may produce different rendered HTML output, I have personally never had any issues. In practice, the only disparity you may face is when your live-preview renderer (that you use while writing Markdown) behaves different than the renderer that produces static HTML/etc.
Asciidoc
Since 2002, Asciidoc offers a powerful set of features that go beyond those of Markdown. For instance, Asciidoc includes block elements that have specific semantic meaning, such as admonitions (“warning: …”), example-, or quotation-blocks. This allows for centralized styling (e.g. with CSS, for HTML output), applied by the renderer to every such block, no matter in which file you used it. Asciidoc also allows including other Asciidoc (.adoc) files, as well as source code files (e.g. .java), with syntax highlighting. Asciidoc can also generate TOCs (Table Of Contents). However, with increased power comes increased complexity. For novices without any prior knowledge, Asciidoc is more difficult to read (and write). If you’re new, consider using WYSIWYG editors like Asciidoc FX and the IntelliJ AsciiDoc plugin.
reStructured Text
Like Asciidoc, reStructured Text (reST) is considerably more powerful than Markdown, having a very similar feature set like Asciidoc. And as you would expect, this also makes the syntax of reST less readable, imposing a steeper learning curve for beginners. Apart from writing pure “.rst” files that contain documentation, reST blocks are often embedded into Python modules (.py files), such that a generator parses Python files too, extracting these blocks and including them in the generated (HTML / PDF) documentation. While the official documentation is verbose, it’s not very readable, and you will probably find better sources. Just look for “restructuredtext cheat sheet” on the net, such as this one. As with Markdown and Asciidoc, reST is well-supported by many existing editors (such as IDEs). There are also WYSIWYG editors like RSTPad with toolbars that offer buttons for the most common formatting tasks.
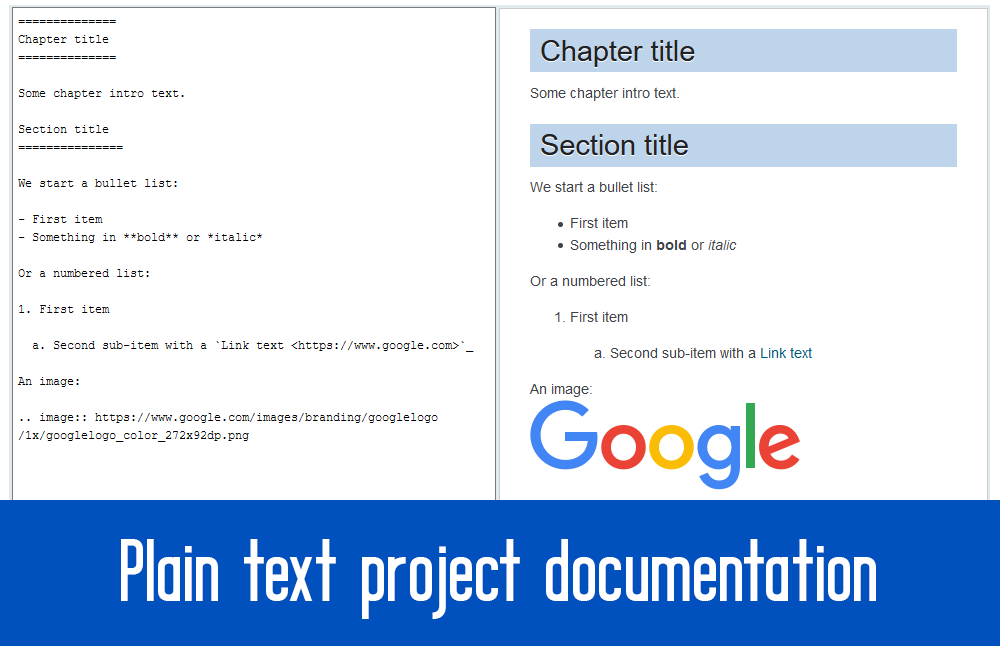
Below you see an exemplary document where I compare the syntax of Markdown, Asciidoc and reStructured Text:
# Chapter title
Some chapter intro text.
## Section title
We start a bullet list:
* First item
* Something in *bold* or _italic_
Or a numbered list:
1. First item
1. Second sub-item with a [Link text](https://www.google.com)
An image:

Code language: PHP (php)==============
Chapter title
==============
Some chapter intro text.
Section title
===============
We start a bullet list:
- First item
- Something in **bold** or *italic*
Or a numbered list:
1. First item
a. Second sub-item with a `Link text <https://www.google.com>`_
An image:
.. image:: https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png
Code language: PHP (php)Chapter title
-------------
Some chapter intro text.
Section title
~~~~~~~~~~~~~
We start a bullet list:
* First item
* Something in *bold* or _italic_
Or a numbered list:
1. First item
a. Second sub-item with a https://www.google.com[Link text]
An image:
image:https://www.google.com/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png[Alt text]
Code language: PHP (php)A more complete syntax comparison is available here. Your final choice is likely to be considerably affected by personal preference.
Choosing a rendering approach
To generate commodity formats (like HTML) for any of the markup languages presented above, there are two common options.
Approach 1: on-the-fly rendering (while browsing the VCS)
With this approach, there is no static build phase. Instead, VCS platforms such as GitLab, GitHub or Gitea convert the md/rst/adoc document to HTML on the fly (on the server), while the user browses through the repository and looks at these files. Even editing such documents on the fly in a “web IDE” is also often possible, including a preview functionality, so that you can check the result before creating a new commit.
The main advantage of this approach is that your users won’t need any tools for viewing or editing. It can all be done in the browser. However, there are a few disadvantages:
Approach 2: CI generation
This approach configures a CI pipeline to produce rendered documentation (in, say, HTML and/or PDF) whenever a new commit was pushed that updated the documentation files. After rendering, documentation is uploaded to a HTTP server. This could be your own web server, a hosted service such as Read The Docs, or the “pages” feature offered by platforms like GitHub or GitLab. The CI automation ensures that the generated documentation stays up-to-date.
Like approach 1, this approach also requires effort to set up. Probably even more than for approach 1, because you now have more flexibility regarding the generation (more details below).
The advantages are:
Tool support for generating documentation
Choosing a markup language for your documentation cannot happen in isolation. You also need to be evaluate the tools that convert the documents.
Tools for approach 1 (on-the-fly rendering)
The table below illustrates the markup language support per VCS platform:
| Markdown | reST | Asciidoc | |
| GitLab |  | | |
| GitHub | | | |
| Gitea | | Need to set up external renderer | Need to set up external renderer |
A green check means that live preview and rendering is supported out of the box. As you can see, support by most platforms is already complete, only Gitea requires a bit of administrative work.
Tools for approach 2 (CI generation)
Depending on the markup language, there may be a huge selection of available generators.
For Markdown there is a huge choice of generators, like Docsify, Daux, MkDocs, Hugo, Jekyll, VuePress, or mdBook. Most of them are static site generators which support Markdown files as inputs, and produce a set of static HTML pages, wrapped in a beautiful theme. Many of them come with integrated search functionality. See here for a list of many other page generators, many of which also support Markdown. Note that those generators are not suited to generate (print) document formats such as PDF or ePub! However, some generators (like Daux) can also create a single (long) HTML file that includes the contents of all your Markdown files, which you can then convert to PDF with various tools, like Gotenberg.
For reST the primarily used generator is Sphinx (not to be confused with the Sphinx search engine or the speech recognition engine). Sphinx supports a large number of output formats. It can render to HTML, split into a separate HTML page per section, with a index page showing the TOC, but can also export a single-page HTML file. Various document formats are also supported, like PDF (via rinohtype or LaTeX, followed by converting .tex files to PDF), or ePub. See here for a full list. The multi-page HTML export includes a full-text search box, out of the box. Sphinx extends the reST syntax by additional, Sphinx-specific elements, like a TOC. Sphinx is very flexible in its configuration, and comes with several built-in themes, but you can also use third-party themes. If your docs are for an open source project, you may use the Read The Docs service for hosting your documentation. By the way, Sphinx also supports Markdown!
Finally, for Asciidoc the primary tool is Asciidoctor. Asciidoctor only supports Asciidoc files, which it converts to various formats, including PDF, ePub, LaTeX and HTML. Note that Asciidoctor focuses on (print) document formats. It always generates single-file documents by default (see e.g. the official user manual). In my opinion, this is not a good fit for reading documents in a web browser. While surfing, I would expect short pages, where clicking and moving the scrollbar does not require a high degree of hand-eye coordination. The single document generated by Asciidoctor does not include any search functionality, since you can just use your browser’s integrated search. If you really want to generate a multi-page HTML documentation from Asciidoc, you have two options. You can either use Antora, which lets you define your own navigation structure. Or you use this plug-in which forces Asciidoctor to render multiple HTML pages (split by sections), but will lack search functionality. Others have also attempted to use Hugo, since it added support for Asciidoctor, but the process is not streamlined and involves a lot of hacking. Just take a look at various articles which you can find by searching for “hugo asciidoc”.
VCS branching options
When you put documentation files into VCS, you have two options regarding branching: you can either create a separate “orphan” branch for your documentation (which shares no history with your other code-related branches), or you use the same branch for code and documentation. The advantages of having an orphaned branch are:
The disadvantages of an orphaned branch are:
Conclusion
Using plain text documentation with markup notation stored in a VCS has clear advantages over using proprietary formats. Most notably, you get the ability to see how documentation evolved, including graphics, and you can better understand changes that apply to multiple files.
However, the transition comes at a cost, both for your users and the admin who selects and sets up the tool chain. Your non-technical (non-developer) users need to learn a few Git basics. Even if they use a nice web IDE (like the one offered by GitLab), they still need to understand what commits are and how to navigate the Git log. The admin will initially have a lot more work, as she will have to evaluate which markup language to choose, and which rendering approach to use. Guides like the one written by Write The Docs can help you get started.
If you are the admin, make sure to first gather requirements from your team (both the contributors and the readers), which helps you narrow down your selection of the markup language or tools. Make sure to show them the markup syntax of the different markup languages, so that they get a feeling for it. For instance, you might gather requirements such as …
- “We only need print documentation as PDF” -> Asciidoctor or Sphinx are the ideal choice,
- “We don’t care about print documentation, we only need online documentation” -> Markdown is also in the mix,
- “This reST syntax looks ugly, we don’t want it” -> you could still use Sphinx with Markdown, or Asciidoc, or Markdown with some static page generator,
- “We are not willing to learn Git” or “We don’t care if we don’t understand how documentation evolved” -> you should not bother introducing plain text documentation at all. Don’t cast pearls before swine ;).
A few final remarks about the three presented markup languages:
- Markdown is the right choice if you target a web page experience. The philosophy here is to use write smaller documents (rendered to shorter pages). Consequently, Markdown does not have an
includecommand, in contrast to reST and Asciidoc, because you would not need it for short pages anyway. Note that some page generators, such as Docsify, use Markdown flavors which do have this command anyway. Markdown’s strength is its simplicity (-> easy to learn), and the large tool support. However, the latter is also a downside, as you may get stuck in analysis paralysis. For instance, should you use Jekyll, Hugo, Docsify, or something else? - With reStructured Text, you won’t need to spend much time on tool selection – there is only Sphinx. Sphinx exports to both web-friendly, multi-page HTML, as well as print-friendly document formats. If you cannot stomach the reST syntax, you may want to experiment with Sphinx’s Markdown support.
- Asciidoc is limited to Asciidoctor, which is optimized for print-friendly formats. If you want to use Asciidoc and publish it on the web, you’ll have to pave the way and experiment with page generators, for which you define your own navigation structure, e.g. Hugo or Antora.
In the end, your choice will be a mixture of requirement fitness and personal preferences. Don’t expect that you make the perfect choice right away. You can still change horses midstream, with tools like Pandoc which convert files between different markup formats. If you plan to include plain text diagrams (using formats like PlantUML), then don’t worry: this is possible with all three markup languages.